Quote:
Originally Posted by xXziroXx
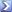
The problem with those nodes is that they're technically closer to the target, thus have a lower F score. I'm not quite sure what I can do to change that.
|
There's a problem with your algorithm. With the way A* works, it will try those nodes first because of their low score, but will eventually correct itself once it realizes that they are not actually part of the "best" path.
It's been a while since I've done any pathfinding work, but I'm guessing that your problem has to do with fixing parent nodes as you find better paths. I actually used the same guide as you when creating my version of A*...this line sums up what I'm talking about pretty nicely:
Quote:
6) If an adjacent square is already on the open list, check to see if this path to that square is a better one. In other words, check to see if the G score for that square is lower if we use the current square to get there. If not, don’t do anything.
On the other hand, if the G cost of the new path is lower, change the parent of the adjacent square to the selected square (in the diagram above, change the direction of the pointer to point at the selected square). Finally, recalculate both the F and G scores of that square. If this seems confusing, you will see it illustrated below.
|
It could be something else, but I had the same problem with not correcting parent nodes.
edit: It helps to see the path that it's creating visually. Try drawing the nodes of the final path, so you can see where it's adding nodes that it shouldn't be adding.